 20 mins
20 minsLight Clients offer a trust-minimized way for users to easily and conveniently access the blockchain, without any reliance on third parties.

While decentralization may be the fundamental property of blockchains, it isn't an end goal in itself. Instead, it's pursued—often at the expense of other desirable properties like scalability—for the emergent properties it begets: trustlessness, permissionlessness, and censorship resistance. These combined properties grant crypto users self-sovereign ownership and access to their wealth and data—that is, at least, in theory.
In reality, most crypto users today are non-committed, connecting to blockchains via a single Remote Procedure Call (RPC) provider maintained by a centralized entity that connects to a small cartel of nodes.
Doing this, while convenient, beats the whole point of disintermediation. Satoshi launched Bitcoin to solve the entrenched financial system's reliance on trusted third parties. "The root problem with conventional currency is all the trust that's required to make it work. The central bank must be trusted not to debase the currency, but the history of fiat currencies is full of breaches of that trust," they wrote in the Bitcoin whitepaper.
To that point, the dangers of centralization and reliance on trusted third parties aren't just theoretical or out in the future but have already been materialized today. For example, immediately after OFAC sanctioned TornadoCash's smart contracts in August 2022, Alchemy and Infura—centralized RPC providers hosting over 60% of Ethereum nodes—blocked users from interacting with the privacy protocol. This meant that anyone using the most popular crypto wallet, MetaMask, under default settings couldn't access what is otherwise a decentralized application running on the largest smart contract platform, Ethereum.

Alchemy and Infura exclusively rely on AWS to host their nodes. (Chart: ethernodes.org)
Beyond censorship, relying on centralized RPCs to access blockchains exposes users to data collection and various types of data manipulation attacks that hinder privacy and could lead to loss of funds. This is why running a full node is so important: it grants users direct, trustless access to the chain, enhancing both the network’s and a user’s security. However, due to the intense resource requirements, running a full node isn’t always as simple as it sounds. Hence, developers have invested significant resources into researching and making light clients as lightweight as possible, which is what this text will be about.
Clients vs. Nodes: What’s the Difference?
To understand the difference between nodes and clients and how the latter work, it’s first worth going over some blockchain basics.
A blockchain is a public database that is updated and replicated across a distributed network of computers. The term "block" in the context of blockchains refers to standardized, validated batches of data that store transaction and state information. When someone sends cryptocurrency to someone else, that transaction needs to be included in a block to be "confirmed" or settled with finality. Final settlement in this context means that the block containing the transaction has been validated by a miner or validator and recognized as such by all other computers in the network. The term "chain" refers to how blocks are recorded in the ledger, where each subsequent block is cryptographically linked with the previous parent block, forming an immutable chain of blocks. The history of the chain is said to be immutable because the data in a block can't be changed without changing all subsequent blocks, which would require consensus among the majority of the network’s computers.
These computers are called nodes. They are running computer software called a client that allows them to verify data against the protocol’s rules and receive and broadcast information to other nodes running the same client, forming a network. The client software is necessary to access blockchain networks, whereas the nodes help maintain the network by independently enforcing the protocol's rules.
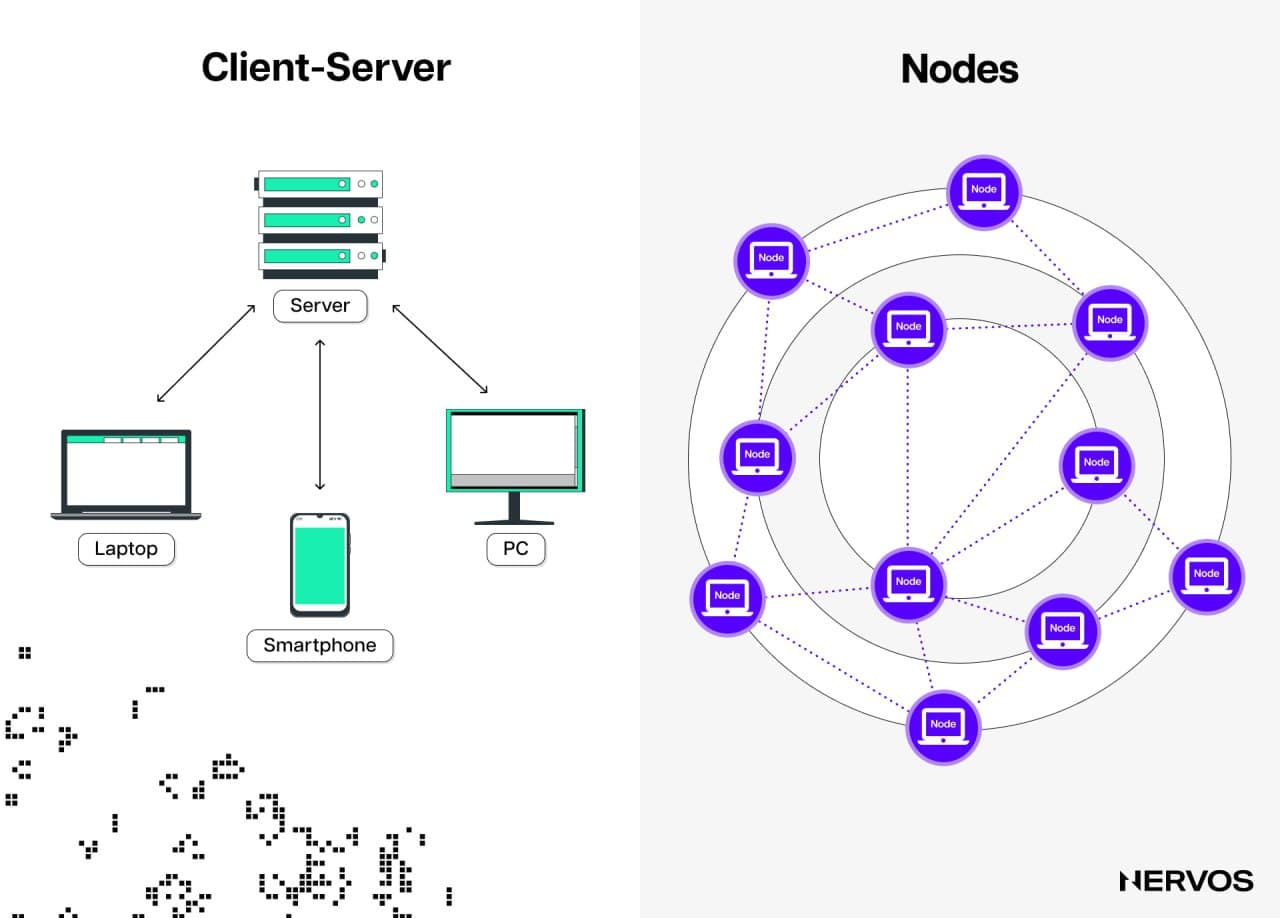
To run a blockchain node, users need to download one of the clients needed to access that specific blockchain. For example, to run a Bitcoin node, users must download the latest version of the Bitcoin Core client, whereas to run an Ethereum node, they can choose between several production-level Ethereum clients, the most popular of which currently is Geth (go-ethereum).
To summarize, if users want to interact with the Ethereum protocol, for example, they can either (i) run a node or (ii) use a third-party RPC node provider such as Infura, Alchemy, or others. The first method gives the users direct, trustless access to the protocol but requires more computing and storage resources. In contrast, the latter is less resource-intensive (hence why it’s the default for most users) but introduces trusted third-party dependencies. The third option is running light clients, which seek to strike the perfect balance between the two.
The Different Types of Nodes: Full vs. Light Nodes
There are different types of nodes that interpret data differently and offer different methods for synchronization, which refers to how quickly nodes can get up-to-speed with the latest state of the blockchain.
Moreover, node types also differ between blockchains. For example, on the largest Proof-of-Stake-based smart contract platform, Ethereum, clients can run three different types of nodes: light, full, and archive. On the other hand, on the largest Proof-of-Work-based blockchain, Bitcoin, clients can run only full and light nodes, also called Simplified Payment Verification or SPV nodes. Because Bitcoin and Ethereum utilize different consensus algorithms and process data differently, the different types of nodes or clients also operate differently.
Full Nodes
Running a full node is the most secure, trustless, private, and censorship-resistant way to interact with blockchains.
In broad terms, the term “full node” refers to a computer that stores and synchronizes a full copy of the blockchain and participates in the consensus process by independently validating transactions and blocks and relaying them to other nodes in the network. Moreover, some full nodes also support light nodes by giving them access to the peer-to-peer network and allowing them to query data and transmit transactions.

Because full nodes download, verify, and store each block's full body and state data, running them requires significant storage, memory, and CPU power. For instance, the minimum requirements for running a full Ethereum node are a 2 TB SSD, 8 GB of RAM, and an Intel 7th generation processor or higher. For Bitcoin, the full node requirements are much lower and include 2 GB RAM, 500 GB of free disk space, and a low-tier CPU.
While these requirements may not seem too wild today, it’s worth remembering that the size of blockchains is constantly growing, increasing the computation and storage burden on nodes. For instance, Bitcoin has grown to around 500 GB in over 14 years, while Ethereum has grown to over 1 TB in eight years. In a bid to combat this problem—also known as state bloat or state explosion—and remain as decentralized as possible, different blockchains have employed or are actively working on different solutions, including capping the block size and block times, state pruning, state rent, and statelessness. For example, unlike archival nodes, Ethereum full nodes prune the historical state data and only store the historical transaction data and the current state; hence, the storage requirement for running them is 2 instead of 15 TB.
In either case, full nodes can’t be run on mobile phones or inside browsers, significantly hurting their adoption rates and blockchains’ decentralization and security.
Light Nodes
Light nodes are computers that access blockchains via light clients. They only download the block headers instead of downloading and verifying every block's full body and state data and storing the entire ledger copy.
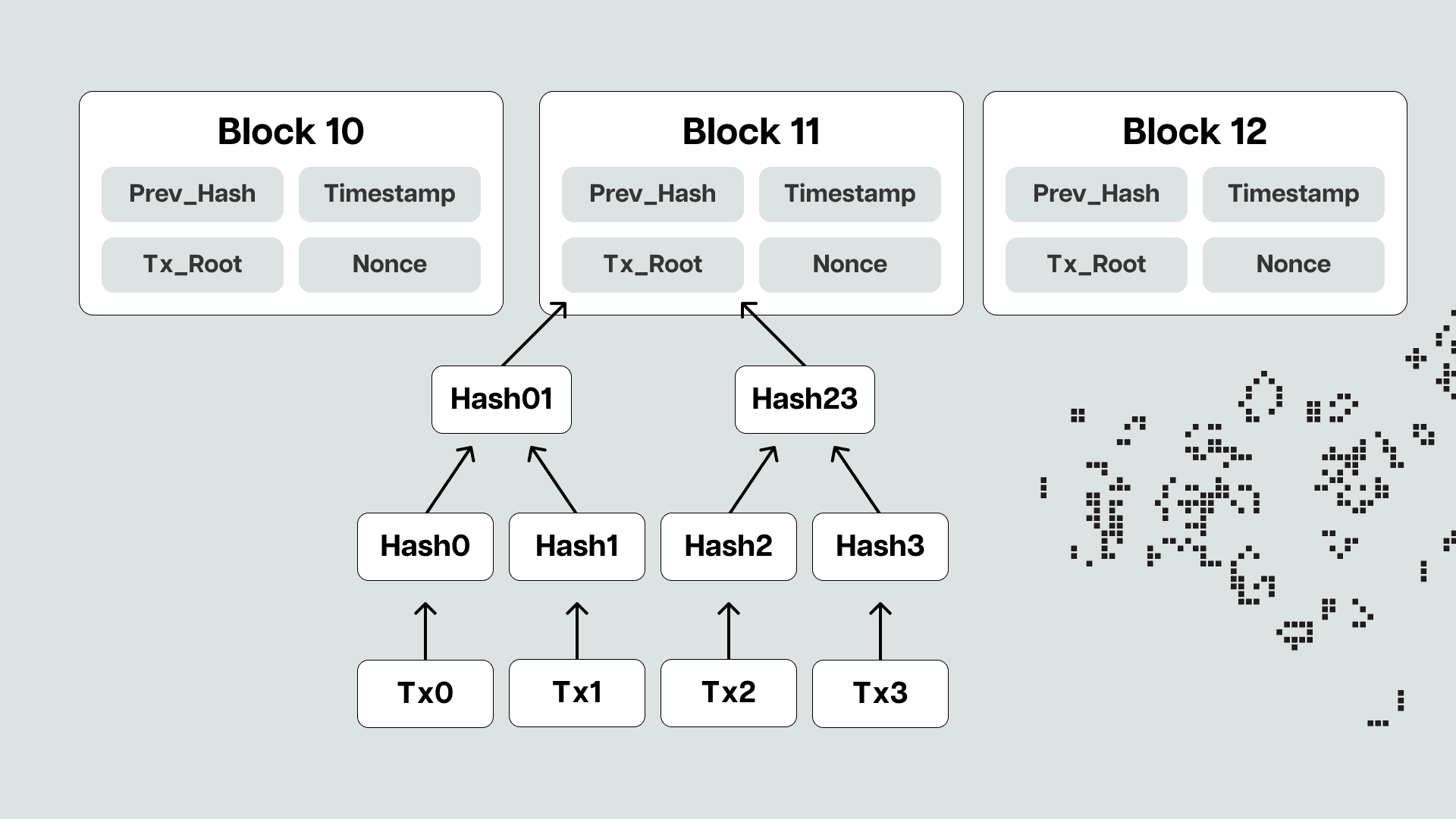
For the uninitiated, a block's structure is broadly divided into a header and a body. In oversimplified terms, the block's body contains the full list of transactions, whereas the headers only contain (among other metadata, like the parent block's hash) the transaction and state roots.
For example, Bitcoin block headers contain only one root, the Merkle tree root of all the block's transactions. In cryptography and computer science, a Merkle tree is a hash-based data structure that allows efficient and secure verification of the contents of large data sets. For context, the average Bitcoin transaction is around 250 bytes, with a full block containing a maximum of about 2,000 transactions. In comparison, the total size of a Bitcoin block's header is about 80 bytes, with the Merkle root weighing only 32 bytes.

On the other hand, Ethereum block headers contain two roots, one state and one transaction root, where the former references the root hash of the state tree (a modified version of a Merkle tree), while the latter references the root hash of the transaction tree. The state tree is a compact data structure that stores the current state of the Ethereum network, including contract storage data and the balance and nonce of all accounts, while the transaction tree contains the hashes of all transactions within the block.

Because the Merkle roots of the respective state and transaction trees contain all of the state and transaction data in a condensed but easily verifiable format, light nodes can independently verify transactions by only downloading the headers. This means that light nodes must still get the block data or headers from some provider, be that a direct connection to a full node (typical in Bitcoin) or an RPC (typical in Ethereum), but don’t have to trust them blindly. Instead, they can independently verify transactions while leveraging a fraction of the storage and computing requirements necessary for running full nodes. Naturally, the security assumptions light nodes must rely on are higher than those of full nodes as they don’t participate directly in the consensus process.
How do Light Clients Work?
Light clients are an important infrastructural component of blockchains. They allow users to independently verify transactions without downloading and processing whole blocks or blindly trusting their data providers while using only a tiny fraction of the hardware requirements necessary for running full nodes. In other words, they aim to strike the “right balance” between the convenience of remote clients and the trustlessness and security of full clients without making huge compromises on either front.
While light clients can be used for different things, including building trustless cross-chain bridges, they’re typically discussed in the context of wallets. At a high level, wallets need to (i) track the tip of the chain, (ii) check account balance and nonce, (iii) read contract information like token balances, (iv) estimate transaction fees, (v) send transactions, and (vi) monitor pending transactions. To do that, a wallet must interact with the blockchain by running a full, light, or remote client.
Running a full node for the sole purpose of using a wallet is obviously out of the question for a vast majority of users. Getting the aforementioned data from a third-party RPC provider via a remote client is super convenient—hence why most users opt for it—but requires a high degree of trust, making it insecure. This leaves light clients, which are trustless, secure, and lightweight enough to run on mobile devices, hardware wallets, or browsers.
Light Clients and Proof-of-Stake
One of the primary functionalities of Ethereum light clients is simplified blockchain synchronization. Instead of downloading entire blocks, Ethereum light clients employ a header-first synchronization approach, significantly reducing the resources and time it takes to get up-to-speed with the tip of the chain.
To verify transactions, light clients only need to check them against the transaction root of the Merkle tree contained in the block headers. If the headers are legitimate, the transaction verification process is simple, as all the necessary metadata is compressed within the root. However, because clients can't—for obvious security reasons—assume that the headers are legitimate, they must verify them independently.
However, verifying headers in Proof-of-Stake-based blockchains like Ethereum is somewhat more complicated than in Proof-of-Work, as the light clients must not only verify the previous header but also the previous state. Namely, to verify a header, Ethereum light clients must verify (i) basic things, including previous hashes, timestamps, and formats; (ii) validator set information, which is part of the state; (iii) validator votes; and (iv) whether those votes are over two-thirds of the shares.
Verifying a header is trickier than verifying a transaction because part of the data needing verification depends on the previous header. For instance, the previous block's hash can only be known by verifying the previous block's header, and the validator set information can only be verified by verifying the state of the previous block. This means that for a light client to be sure that a specific header is legitimate, it would need to recursively verify all the headers back to the Genesis block’s header.
Even though headers are much smaller than whole blocks, and this process is significantly faster than downloading the entire chain as full nodes do, light clients still can't afford to do this and need to synchronize much faster. For this reason, new infrastructure specifically designed to support light clients was introduced with Ethereum's move to Proof-of-Stake.
Namely, Ethereum light clients can leverage the Beacon chain's so-called "sync committee" and "weak subjectivity points" to sync up with the tip of the chain much more efficiently. For the uninitiated, the Beacon chain refers to Ethereum's consensus layer, a peer-to-peer network of nodes running consensus clients that handle block gossip (propagation) and consensus logic. Transaction gossiping, execution, and state management are done by the execution layer, which is a peer-to-peer network of computers running execution clients. The two layers can communicate with one another through the Engine API, with Ethereum nodes being able to run any combination of clients (i.e., a light consensus and a full execution client).
The sync committee is a randomly selected subset of 512 validators that serve for about 27 hours. The committees sign the headers of recent blocks and include their aggregated signature in them. The headers also contain a list of validators expected to participate in the following sync committee. This means that when light clients receive a header, they can quickly see that a sync committee has signed it and also check whether the sync committee is genuine by comparing it to the one they were told to expect in the previous block.
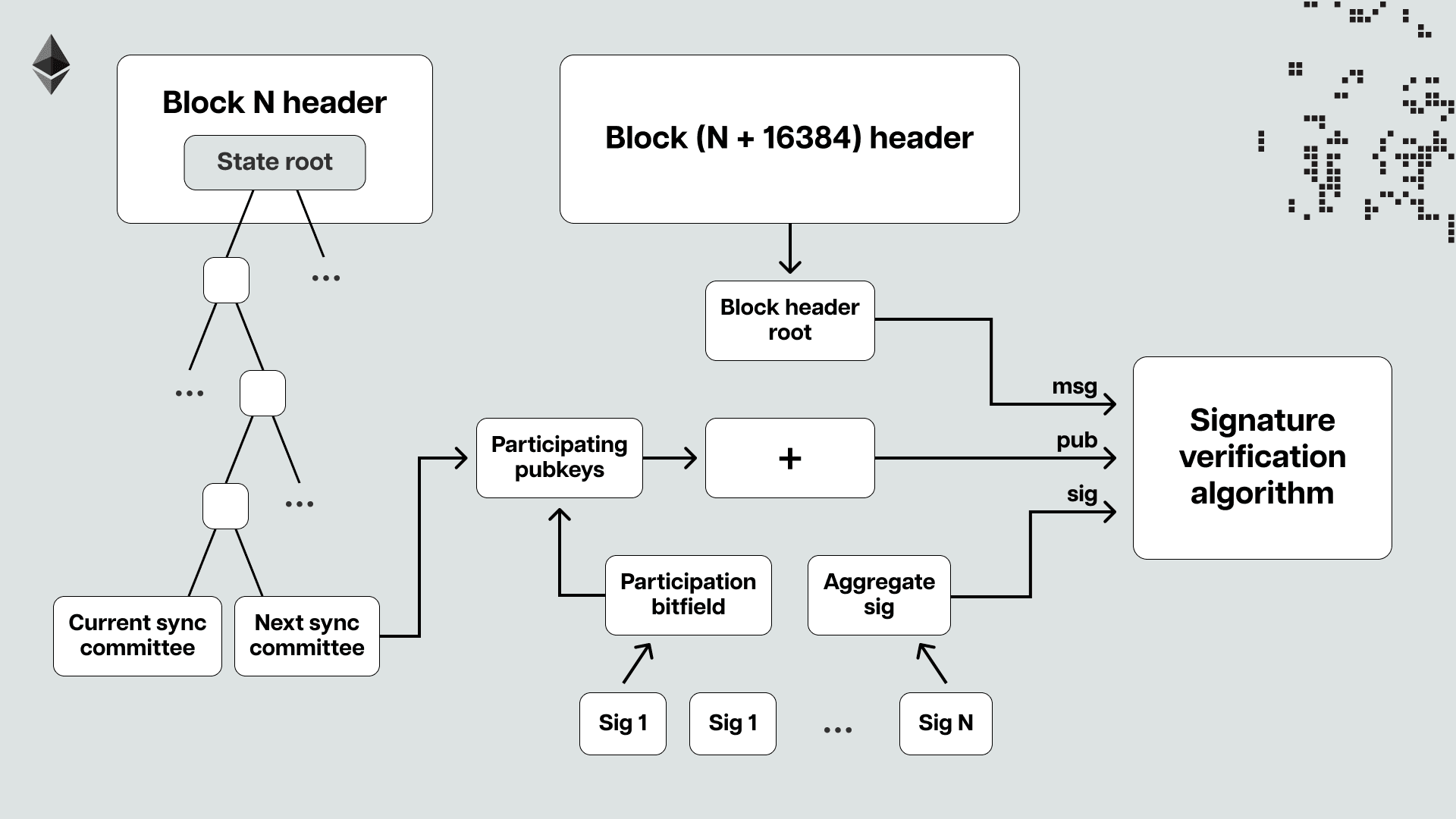
Important to note here is that the sync committee doesn’t hold the same security guarantees as the entire Ethereum validator set, as it was specifically introduced as part of the Light Client Protocol to help reduce the computational costs of verifying the validity of headers. Instead of verifying over 400,000 validator signatures, light clients can verify only the signatures of the 512 randomly selected validators of the rotating sync committees, significantly reducing the computational overhead. However, light clients must assume that most of the sync committee validators are honest, as there’s no slashing for them. To that point, it’s highly statistically improbable that the sync committee would sign off on an invalid block header if a significant portion of the entire Ethereum validator set is honest.
This means that if more than two-thirds of the committee sign a given header, it is extremely likely that that block is in the canonical chain. In other words, if a light client knows the makeup of the current sync committee, it can confidently track the head of the chain by asking a provider (a full node or an RPC) for the most recent sync committee signature. However, how do light clients obtain knowledge about the most recent sync committee? They get it from the previous sync committee.
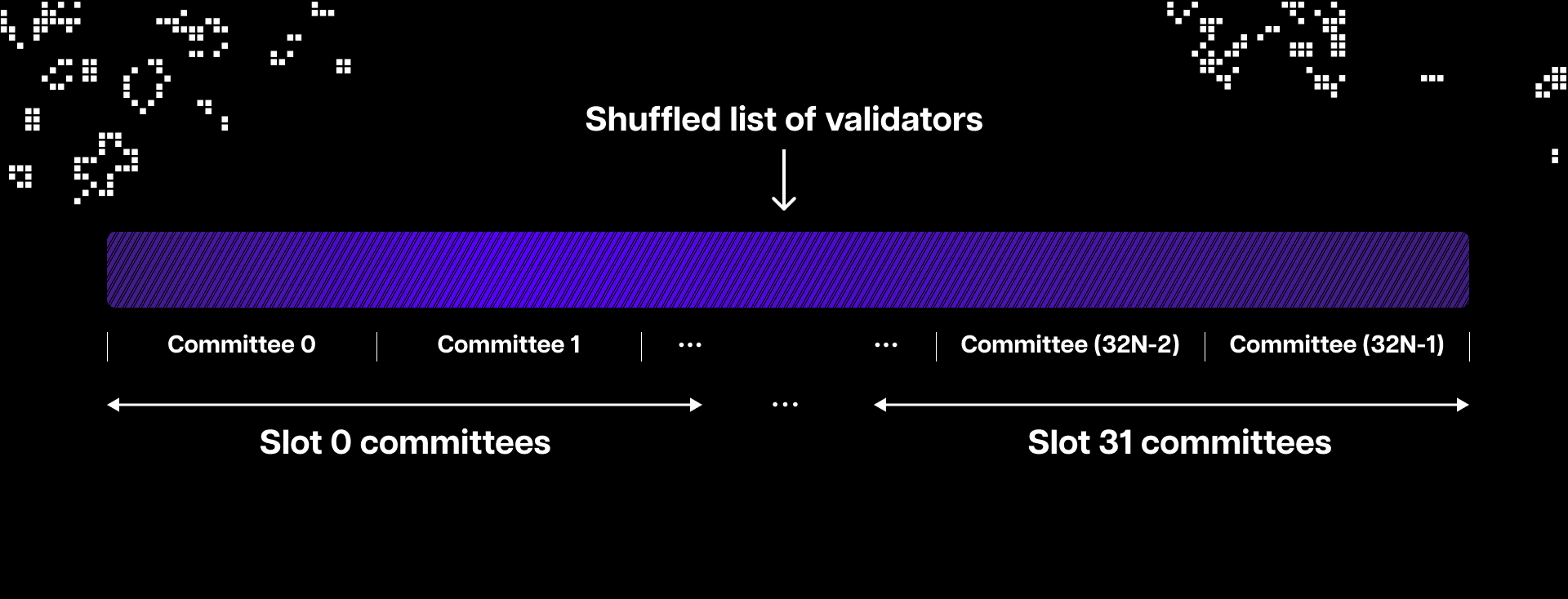
As already explained, every 27 hours, the sync committee changes and passes on the power to sign the latest block to the next sync committee. To get the previous sync committee, light clients need the sync committee before that one, and so on, all the way back to the Merge transition block and the first-ever sync committee. If they start from there, light clients can move up the chain's history 27 hours or one sync committee at a time all the way up to the present sync committee.
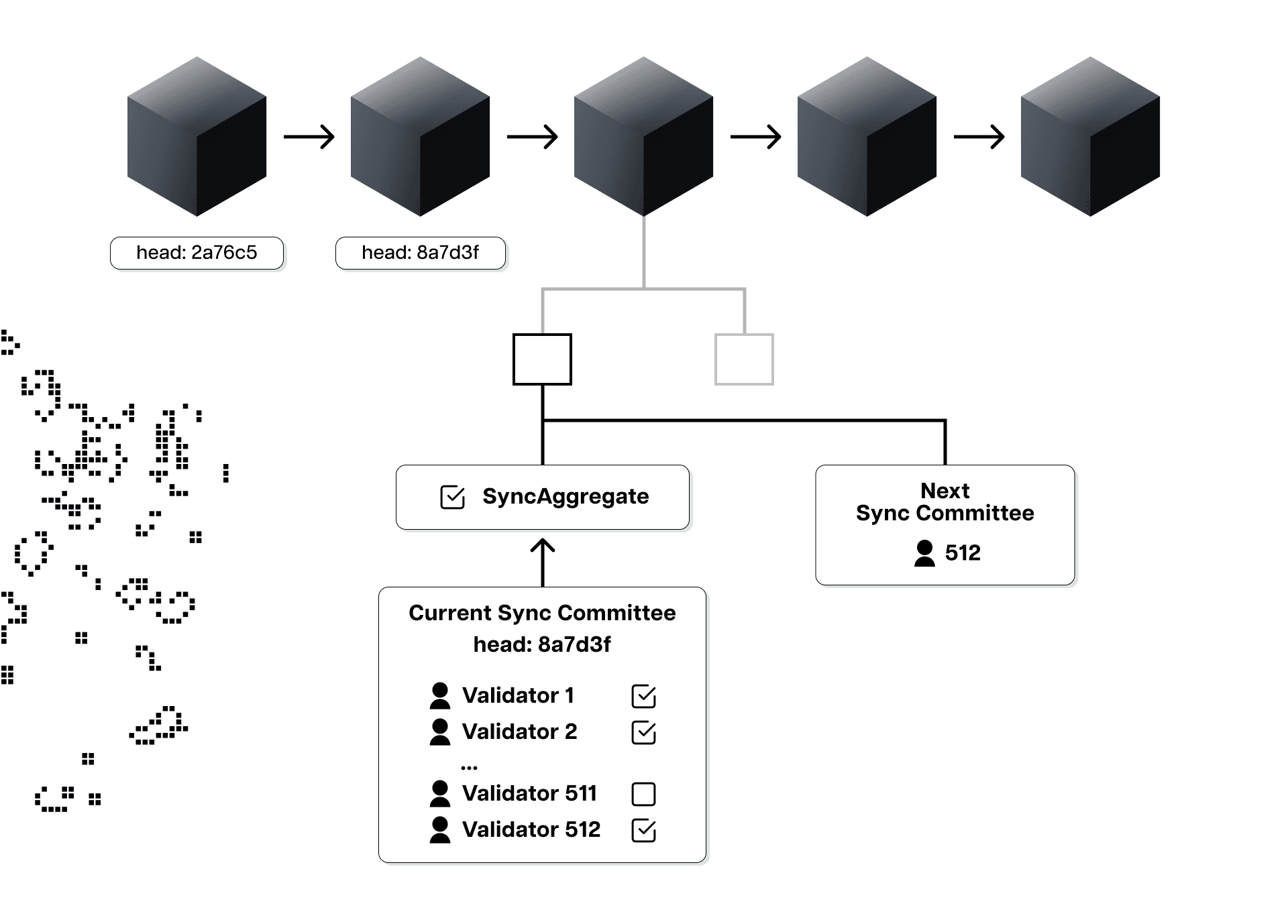
The aggregated signature of each sync committee is super small, about 25 kilobytes, meaning it takes clients little storage and effort to sync to the latest block header. To speed up this process even more, light clients can leverage weak subjectivity checkpoints and start synchronizing from a more recent “universal truth”—a block all nodes agree belongs in the canonical chain—instead of the Merge transition block. Theoretically, this method allows light clients to safely and trustlessly sync with the tip of the chain within a few seconds, requiring negligent storage space.
That concludes how Ethereum light clients work in theory. In practice, several clients are in development, none of which are currently production-ready. Much work is also being done to improve how light clients can access Ethereum data. At the moment, light clients rely on RPCs for data availability using a client/server model, but in the future, they could access data in a more decentralized way by leveraging peer-to-peer gossip protocols.
Bitcoin Light Clients (SPV Clients)
Because Proof-of-Work is objective and difficult to fake, light or SPV clients in blockchains like Bitcoin are much more straightforward.
Instead of downloading entire blocks from a full node and maintaining a copy of the entire ledger, Bitcoin SPV clients only download the block headers. This amounts to a much smaller synchronization overhead: 80 bytes vs. around 2 megabytes per block. Like in Ethereum, Bitcoin light clients verify transactions by checking them against the root of the Merkle tree that contains the hashed metadata of all the block’s transactions. However, to verify the header itself, the SPV client needs to download and recursively verify block headers all the way back to the Genesis block. Luckily, verifying the headers’ validity is a very simple process, as the light clients only need to check for the Proof-of-Work contained in the headers and then follow the “longest chain” rule to ensure they’re on the canonical chain.
Important to note here is that SPV clients can’t know whether all the transactions are valid or if the consensus rules are being followed. Instead, they assume that the chain with the most cumulative hash power behind it is the canonical chain and follows all the protocol’s rules. Because proofs of work are super expensive for miners to generate, the light nodes can safely assume that all the transactions in the longest chain are valid and that the majority of the miners or the hash power support the same valid chain.
As Satoshi wrote in the white paper, “[the SPV client] can't check the transaction for himself, but by linking it to a place in the chain, he can see that a network node has accepted it, and blocks added after it further confirm the network has accepted it." In other words, SPV clients trust that the more blocks are added on top of a specific block X, the more difficult or costly it is to forge the transactions inside block X. When light clients need to verify the inclusion of a specific transaction in the ledger, they leverage the peer-to-peer gossip protocol to ask a full node for an SPV proof of the chain and a path to the Merkle tree committed to the header. This is very different from “thick” or full clients that verify whether a transaction’s inputs are unspent by actually checking the whole chain up to that block height.
Critical to understanding here is that, unlike Ethereum light clients that can leverage weak subjectivity points and sync committees to skip ahead in the chain one 27-hour period at a time, Bitcoin SPV clients can’t do this and must download the entire chain of headers back to the Genesis. This means there’s still a significant overhead for the most resource-limited clients, especially when considering that the resource requirements for running light clients grow linearly with the number of blocks. This is already a major concern for Proof-of-Work blockchains with fast block intervals and larger block headers.
What are FlyClients?
In 2019, a team of researchers proposed a design for a super-light client, called FlyClient, that aims to solve the overhead issue plaguing current Proof-of-Work light clients.
The overarching idea behind the FlyClient design is to allow super-light clients to download only a sublinear amount of information. By downloading a logarithmic (think the opposite of exponential) instead of a linearly increasing number of headers to verify the validity of the chain, a FlyClient can efficiently verify the inclusion of any transaction on the chain by storing only a single block and do so with stronger security assumptions than SPV clients.
The FlyClient protocols do this by utilizing several innovations, including a novel, append-only data structure known as a Merkle Mountain Range or MMR. Without going too deep into the technical details, MMRs allow the full nodes or provers to prove to the FlyClients or verifiers that the most recent block header they’ve sent is indeed the tip of the canonical chain and not a forked invalid chain.
Suppose a FlyCient receives conflicting information from different full nodes, like two different headers at the same block height. In that case, the client can do a probabilistic sampling of a logarithmic number of block headers, checking the proof of work to find which node holds the honest chain. This mechanism, along with clever cryptography embedded in MMRs, allows FlyClients to stay up to speed with the tip of the honest chain with higher security assumptions and a fraction of the overhead requirements of even SPV clients.
A FlyClient protocol is currently being implemented on Nervos’ Layer 1 blockchain, Common Knowledge Base (CKB). This FlyClient implementation—the first of its kind for NC-Max—will allow users to run trustless CKB nodes on any device, including old mobile phones.
Conclusion
Full nodes, while embodying the epitome of security, present logistical challenges due to their resource demands. Light clients, in contrast, offer a streamlined approach, ensuring efficient blockchain interactions without the hefty requirements.
The mechanisms employed by Ethereum's light clients and Bitcoin's SPV clients showcase the industry’s dedication to refining and optimizing blockchain accessibility. The advent of FlyClients, with their innovative design, further emphasizes the strides being made in the realm of light clients. In any case, light clients remain a critical infrastructural component of the industry, as without them, trustless blockchain interaction wouldn’t be possible for most crypto users.
